Main Menu
Basic RSP Concepts
What is an RSP script?
RSP stands for REBOL Server Pages. It is a templating system allowing programmers to simply mix static parts with code, in order to deliver dynamic content. It is a very common approach in the web programming world as demonstrated by the popularity of PHP.
So, every RSP page contains static parts (the template) and code parts delimited by <% and %> sequences.
For example, test.rsp file that would contain:
the current time is <% print now/time %>
will produce if called by a browser, of from the REBOL console:
the current time is 17:58:36
Notice that it was necessary to use PRINT function to insert the value into the resulting string. RSP needs you to explicitly indicate which values will be inserted into the response buffer. So, producing dynamic content is a matter of adding content to the response buffer by code. This can be achieved using several methods:
- using PRINT, PROBE, EMIT functions
- directly altering the response BUFFER (it's a string! series).
- using short-cut evaluation: <%= value %> (same as PRINT)
- using short-cut reduced evaluation: <%? value %> (same as EMIT)
You can mix these methods together in your RSP scripts. This example:
<%
either size < 1024 [
print ["File size is:" size "Bytes"]
][
print ["File size is:" size / 1024 "Kilobytes"]
]
%>
will produce the same output as:
<%either size < 1024 [%>
File size is: <%= size %> Bytes
<%][%>
File size is: <%= size / 1024 %> Kilobytes
<%]%>
or even this shorter form:
File size is: <%? either size < 1024 [[size "Bytes"]][[size / 1024 "Kilobytes"]] %>
Note: There's no requirement for extra space between your code and <%...%> delimiters except for readability. So, this example:
<%=mold now%>
is correct syntax too.
It is also possible to produce your own content by replacing the response buffer with your own series (binary! or string!). The typical use case for this is dynamically producing an image (for a Captcha for example). See BUFFER documentation for more information and example.
Also, remember that RSP templates are not limited to HTML, they can be used with any other text-based file formats like XML, CSS, Javascript/JSON,...(just be sure to set the proper response's Content-Type in such cases)
No-template scripts
It is also possible to use plain REBOL scripts to generate dynamic content. All files with .r extension within a domain or webapp will be run as no-template scripts by Cheyenne.
It is a similar to CGI scripting approach, but without the need for a shebang line nor a Content-Type header. The whole RSP API is available to use. This scripting form can be useful when converting existing CGI scripts to benefit from the RSP execution environment, without having to make much changes. Example of such script:
REBOL [
Title: "Simple REBOL script run in a RSP environment"
]
print "<HTML><UL>"
either empty? request/content [
emit "<LI>No variable passed</LI>"
][
foreach [name value] request/content [
emit [<LI><B> name ":"</B> html-encode mold value </LI>]
]
]
print "</UL></HTML>"
Parameters
A common task in RSP scripts is the ability to read parameters passed either by GET in the URL or by POST in the request content part. These parameters and their values can be easily retrieved using the request's CONTENT method. Both GET and POST parameters are accessible with the same method, there's no difference.
For example, to access id parameter from this URL: http://domain.com/test.rsp?id=123, the test.rsp script would look like:
<%= request/content/id %>
An important remark is that if id parameter is not passed in the request (by GET or POST), you need to check for its presence or you'll get a runtime error. So a safe way to access it, would be:
<%= select request/content 'id %>
Remember that request/content is a block! value filled with name/value pairs so, it is possible to use SELECT to access a value.
Validation
Request parameters validation is an important topic, both for correct RSP script security and for safer code. The RSP API offers a simple validation dialect to solve that using the VALIDATE function.
Simple parameters validation looks like this:
<%
invalid?: validate [
name string!
age integer!
]
if invalid? [
print ["These parameters are not valid:" invalid?]
]
%>
Validate will return a list of not-validated parameters, so it's easy to check if requirements are met. Validate will also automatically convert parameters to the specified datatype (or mark them as invalid if it fails). This way, you can be sure of the parameter datatype when you access it without having to convert it yourself. Still, if the parameter is missing in the request, you'll need to use a safer access method.
To work-around this issue, you can use the /full refinement on validate to make it check parameters presence for you. Here's the same example with presence check:
<%
invalid?: validate/full [
name string! *
age integer! -
]
if invalid? [
print ["These parameters are not valid:" invalid?]
]
%>
You can notice that a third column has been added to the validation specification block. It can contain several options:
- a star to mark a mandatory parameter
- a dash to mark an optional parameter
- a value to mark an optional parameter and provide a default value if missing
When a parameter is marked as mandatory, it will be flagged as invalid if missing in the request. An optional parameter can be missing without been flagged and will be added anyway to the request's CONTENT block with a none value. So direct access using request/content/parameter will always be safe when /full refinement is used!
RSP API Objects & Functions
RSP API is fully documented here.
Debugging RSP Scripts
Client-side debugging
RSP scripts can run in a debug mode, displaying a fancy menu bar at top of each page, giving access to request headers and parameters, matched configuration block and session content (if a session is active). There is two ways to activate and deactivate the debug mode:
- add a debug keyword into your host or webapp configuration block
- add a call to debug/on at the beginning of your script (will apply only for current script)
The debug mode will also catch the HTTP redirection, making it easier to inspect request parameters in such cases. This is an example of a page with debug mode activated:
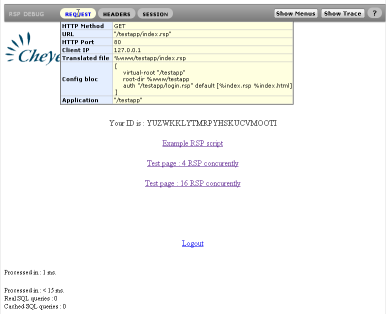
Note: In debug mode, errors will be reported directly in the displayed page, in a popup. In production mode, errors are only logged in the %trace.log file.
Server-side debugging
Even if the debug mode is not active, you can always log debug information on server-side trace file (trace.log), using the provided function:
- debug/print: log a debug message
- debug/probe: log a MOLD-ed value
- ??: log a variable name followed by its molded value
Usage example:
<%
if positive? debug/probe amount [
debug/print ["Withdrawing" amount]
...
]
%>
Note: The trace.log file is always located in the same folder as Cheyenne binary (or same folder as %cheyenne.r if run from sources).
Good Practices
Just a few important and useful things to keep in mind while developing RSP scripts and webapps.
Multiprocess environment
RSP scripts are run in a multiprocess environment, the consequence for RSP scripts, is that you can't expect any word defined in your script to be still defined for another script. It might or might not work depending on the worker running your script. As a rule of thumb, never expect that a variable will survive past the end of the script. This means, no value or variable sharing between RSP scripts. If you need that feature, you need to start a Session first. Alternative options are storing shared data in files (watch out for concurrent accesses) or better, in a database.
Unlike general CGI, RSP worker processes are persistent, so be kind with your usage of memory and in some cases, watch for word! values limit (should be 32K in latest REBOL kernels).
Code caching
It is possible to take advantage of workers process persistence to keep some of your code cached in memory instead of evaluating it each time. A typical use-case is wrapping some script's local functions in a persistent object and ensuring that it will be present in any worker running your code. Caching object example:
<%
unless value? 'my-object [
my-object: context [
... some functions ...
]
]
...
%>
Using such construction at the beginning of a RSP script will allow you to keep my-object cached in memory instead of having to re-construct it on each script call. This works well for simple standalone RSP scripts, but if you need to do that for several scripts working together, you should consider switching to a webapp that will provide you the same benefits but with a more structured approach.
Note: if you edit some code inside such cached object, your changes will not be taken into account, you need to reset workers? processes to apply your changes or run Cheyenne with a non-persistent? worker.
Clean separation of code and static parts
Even if the templating approach is handy, you should try to keep the mixed parts as short as possible to help your scripts be more easily readable by yourself and others. This means gather as much code as possible at the beginning of your RSP script and use minimal REBOL code inside the template. Even better, put your utility functions into separated REBOL scripts and load them using worker-libs? config directive, or switch to webapp container and put them in the private folder.